Intel’s Linux kernel test robot recently flagged a remarkable 3888.9% performance boost in the mainline Linux kernel, detected through the “will-it-scale.per_process_ops” scalability test. This massive increase was recorded on an Intel Xeon Platinum (Cooper Lake) server, highlighting the power of Intel’s automated testing service in identifying both positive and negative performance shifts as new kernel patches are added.
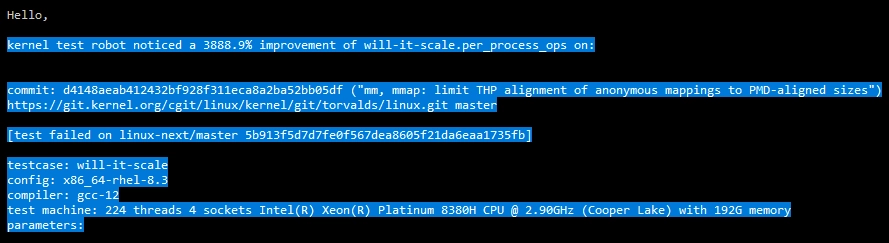
The latest improvement is attributed to a recent commit targeting memory management: “mm, mmap: limit THP alignment of anonymous mappings to PMD-aligned sizes.” The adjustment aims to resolve earlier performance issues related to Transparent Huge Pages (THP) and memory alignment. In particular, it changes how large anonymous memory mappings align to benefit from THP—an optimization that can significantly improve memory handling in certain workloads.
Since commit efa7df3e3bb5 (“mm: align larger anonymous mappings on THP
boundaries”) a mmap() of anonymous memory without a specific address hint
and of at least PMD_SIZE will be aligned to PMD so that it can benefit
from a THP backing page.However this change has been shown to regress some workloads
significantly. [1] reports regressions in various spec benchmarks, with
up to 600% slowdown of the cactusBSSN benchmark on some platforms. The
benchmark seems to create many mappings of 4632kB, which would have merged
to a large THP-backed area before commit efa7df3e3bb5 and now they are
fragmented to multiple areas each aligned to PMD boundary with gaps
between. The regression then seems to be caused mainly due to the
benchmark’s memory access pattern suffering from TLB or cache aliasing due
to the aligned boundaries of the individual areas.Another known regression bisected to commit efa7df3e3bb5 is darktable [2]
[3] and early testing suggests this patch fixes the regression there as
well.To fix the regression but still try to benefit from THP-friendly anonymous
mapping alignment, add a condition that the size of the mapping must be a
multiple of PMD size instead of at least PMD size. In case of many
odd-sized mapping like the cactusBSSN creates, those will stop being
aligned and with gaps between, and instead naturally merge again.
Intel’s testing found that the prior method of aligning memory mappings to PMD boundaries, introduced in December 2023, actually degraded performance for some workloads. Notably, some benchmarks, like cactusBSSN, suffered up to a 600% slowdown due to the new alignment creating fragmented memory areas. This fragmentation led to inefficiencies in memory access, causing issues with cache and TLB (Translation Lookaside Buffer) performance.
The new patch limits THP alignment to cases where the memory mapping size is a multiple of the PMD size, preventing gaps and fragmentation for many workloads, including graphics processing tool darktable. This one-line fix aims to keep the THP benefits intact while avoiding alignment-based performance losses.
Intel’s kernel test robot has been instrumental in identifying this performance regression and fix, emphasizing its value for developers and system administrators working on the Linux kernel.
Like my content? Support me with a tip!